Infant Relation Categorization
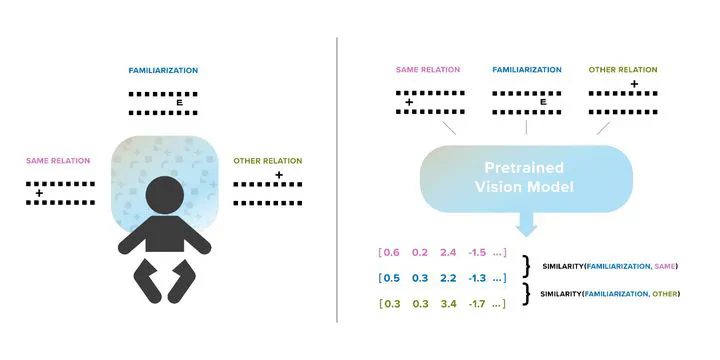 Left: infant relation categorization is studied in the lab using a novelty-preference paradigm. Right: we model this paradigm using deep neural networks.
Left: infant relation categorization is studied in the lab using a novelty-preference paradigm. Right: we model this paradigm using deep neural networks.Spatial relations, such as above, below, between, and containment, are important mediators in children’s understanding of the world (Piaget, 1954). The development of these relational categories in infancy has been extensively studied (Quinn, 2003) yet little is known about their computational underpinnings. Using developmental tests, we examine the extent to which deep neural networks, pretrained on a standard vision benchmark or egocentric video captured from one baby’s perspective, form categorical representations for visual stimuli depicting relations. Notably, the networks did not receive any explicit training on relations. We then analyze whether these networks recover similar patterns to ones identified in the development, such as reproducing the relative difficulty of categorizing different spatial relations and different stimulus abstractions. We find that the networks we evaluate tend to recover many of the patterns observed with the simpler relations of “above versus below” or “between versus outside”, but struggle to match developmental findings related to “containment”. We identify factors in the choice of model architecture, pretraining data, and experimental design that contribute to the extent the networks match developmental patterns, and highlight experimental predictions made by our modeling results. Our results open the door to modeling infants’ earliest categorization abilities with modern machine learning tools and demonstrate the utility and productivity of this approach.
Initially presented at CogSci 2021, and the full journal papere was publised in Cognition.